Distributed Machine Learning Fundamentals: Next Steps
David Crawford / February 17, 2025

![]()
This post is part 6 of my Distributed Machine Learning series, you can go back to any of the posts that are published below:
- Introduction
- Preparing a Model with MLX
- Dataset Preparation
- How to setup MPI
- Distributed Fine Tuning
- Next Steps (👈 this post)
For my final post in this series, it's time to go over some of the common sense for applying distributed machine learning to production products, and answer some good questions. This post won't be as technical as the others, but instead will serve as a resource to help you decide what the best tools are to use, and where to go with your new distributed fundamentals.
Making Decisions
If you're interested in adding a distributed setup to your project, I made a simple flowchart to help determine the best path.

Let's go over the questions posed and the recommendations:
Do you need to do this multiple times?
If your problem only requires you to fine tune or train a model once, and likely not again, then a distributed setup may end up taking longer to implement than just doing the training on a single computer. A narrow or simplified use case doesn't really need a complex setup. I would only recommend distributed for a one time use case, if you're doing it to either learn or prove out a concept for convincing parties to use distributed to save time.
Does training or fine tuning take 1+ hours?
If your training or fine tuning already doesn't take a lot of time to finish, then the time save won't be very noticeable. I would only recommend using distributed if you're going to see some significant real-world time savings, on a factor of hours or more. Otherwise, the effort to implement it outweighs the small gains you might see.
The basic, fully parallel distributed setup
This solution is essentially the one presented in this series. It has its own set of limitations and shouldn't be used as a hammer to every distributed problem. Consider this:
-
This solution requires a fully parallel setup across the network
- Each computer needs its own copy of the model, training data, file paths, etc.
- The network is not resilient to failure, and if one computer goes down it causes disruptions
- MPI needs all the machines to be immediately accessible to begin the process, it's not resilient to modular changes
-
Amdahl's law
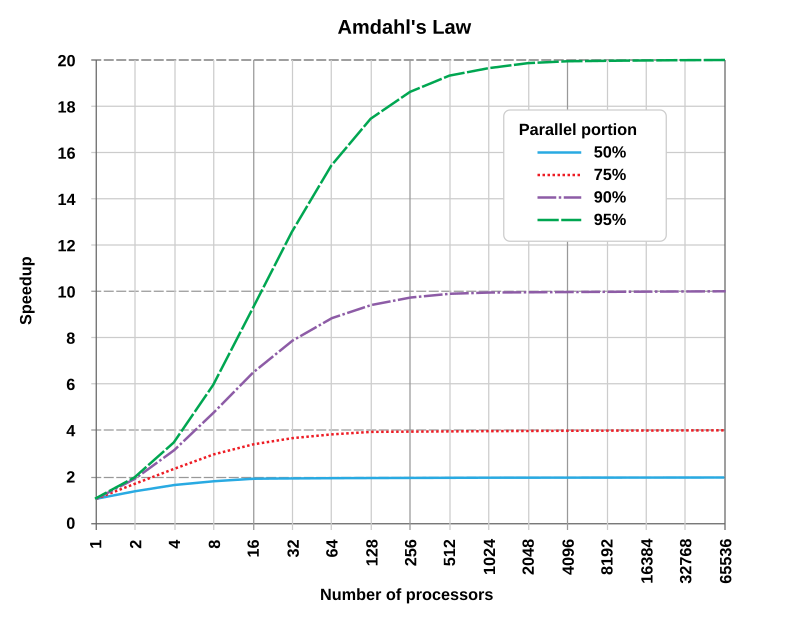
You can't just add 1000 computers to your setup and expect a 1 second training cycle. Amdahl's law tells us that the speedup from parallelization is limited by the sequential portion of the code. If too much computation depends on serialized execution, adding more nodes will have diminishing returns.
- MPI limitations
MPI itself doesn't optimize for deep learning workloads as well as Horovod or DeepSpeed, which are designed specifically for distributed training. With that in mind, why did we use MPI in this series? I chose it because it's the most foundational distributed framework that is the underlying technology for a lot of stuff out there. Understanding MPI gives you the best foundational knowledge to work with more specialized tools, which all use the same principles.
Rule of Thumb: The signs of outgrowing the basic setup
If you don't fit into my flowchart, here are some more considerations to think about. If you find yourself having to use several of these techniques to optimize your basic setup, it's time to move onto a more advanced framework:
- Optimizing batch sizes to reduce synchronization costs
- Using gradient compression techniques to reduce communication overhead
- Using hierarchical communication (e.g., ring-allreduce in Horovod) to improve efficiency
- Using high-speed interconnects (like NVLink or Infiniband) for better network performance
- Choosing asynchronous training where possible to minimize blocking operations
Sharding & A Mature Distributed framework
Considering the limitations of the basic setup, what can we do? What do we do when we need a scalable, advanced solution? This is where we introduce a new term: sharding.
Sharding
This is the technique of dividing a large machine learning model into smaller, more manageable parts (shards) that can be distributed across multiple devices.
There are a couple different types of sharding:
- Tensor (Layer-Wise) Sharding
- Different layers of the model are distributed across multiple devices
- Useful for deep networks where computation at each layer can be parallelized
- Operator (Pipeline) Sharding
- Splits computations (operators) across devices but keeps the model structure intact
- Common in transformer-based models like GPT
- Parameter (Weight) Sharding
- Splits model parameters (weights) across devices
- Reduces memory consumption per device while maintaining full model computation
- Expert (Mixture of Experts - MoE) Sharding
- Different experts (sub-models) are placed on separate devices
- Only a subset of the model is activated per inference, reducing computational load
As you might be feeling from reading this list, sharding is complicated to say the least. It's not something you can just throw together with MPI and expect it to work. Typically, if this is needed, it's best to find a framework that takes care of it for you.
For MLX specifically, this repo is a great resource to get started with sharding.
Mature Frameworks
I mentioned a couple tools previously, but there's a spectrum of involvement you'll need. At the time of writing this, MLX isn't popular enough to have full production frameworks for distributed setups, so below are some other options for you to evaluate:

Horovod - built on top of MPI, but is designed specifically for TensorFlow, Keras, PyTorch, and Apache MXNet

DeepSpeed - built on top of PyTorch, requires CUDA or ROCm, and is designed to optimize training for large models and thousands of GPUs in a distributed setup. It's a great choice if you're working with very large models

AWS Sagemaker - a managed service that makes it easy to train models on AWS infrastructure. It's a great choice if you're looking for a fully managed solution that takes care of the infrastructure for you

Google Vertex AI - same as AWS but with Google infrastructure
Series Conclusion
I hope you've enjoyed this series on distributed machine learning. We've covered the fundamentals that govern the principles around almost all distributed frameworks:
- MLX models and training
- Data curation
- Gradient averaging
- MPI
I hope that you've learned a lot and can make more informed decisions for your next machine learning project.