How to: Machine Learning in the 1980s
David Crawford / February 24, 2025

Pictured above: My grandfather on the left, and my father on the right, working on the same Mac SE/30 decades ago that I use today.
![]()
A couple weeks ago, my colleague Brad Cooley gave a talk to our company about general AI/Machine Learning terms including Object Character Recognition (OCR). He mentioned that OCR was used in the 1980s, and that got me thinking about what machine learning was like back then.
In the 1980s, computers had an incredible lack of resources to work with compared to today. We usually think of machine learning as an incredibly resource intensive task, something that even modern computers can struggle with. So how did people do it back then?
In 1958, Frank Rosenblatt wrote a paper on the perceptron, a simple algorithm that could learn to classify data. The perceptron was a single layer neural network that could learn to classify data into two categories. It was a simple algorithm that could actually be run on a computer with very limited resources, called the Mark 1 Perceptron.

The cool thing about this machine is that inside, it was physically designed like a brain and the human neural network.

Frank Rosenblatt working on the Mark 1 Perceptron
If Frank could do it in the 1950s, I could do it with a 1980s computer. But I needed proof before putting time into this, so I looked through old 1980-1990s computer magazines and journals looking for any mention of at least the existence of OCR.
Evidence
I found two mentions of OCR cited below:

CANDIDATES FOR DISTRIBUTED COMPUTING
Distributed computing will be a great boon to applications where computing power is critical and where the computing task can be split into discrete subtasks. Such applications include the following:
• compiling a new product using a superoptimizing compiler
• solving an optimization problem like placing chips on a board
• generating computer graphics, especially ray tracing
• performing optical character recognition

Mac-Barcode puts you in touch with the unsurpassed benefits of bar code data entry: speed, accuracy and reliability. A technology that is three million times more reliable than keyboard data entry and 300 times more reliable than Optical Character Recognition (OCR).
This was all I needed to know that I could do it.
The Setup
My goal was to create a simple program that can detect if a drawing contains the capital letter A. This is a classic OCR problem, and would require the perceptron algorithm to work with our 4mb of RAM on the Mac SE/30.
In 2022, I wrote a post that goes into developing programs with C on a Mac SE/30, and I don't want to repeat the information, so I'd recommend you give it a read to see how THINK C gets setup, and the environment we're working with.
The program
I originally wanted to draw a letter for our input with MacPaint, however I ran into a lot of problems with how MacPaint automatically compresses images with the PackBits algorithm. I needed the raw binary data of the black and white images, and decompressing PackBits only worked for the first row of pixels unfortunately. So I came up with another way to do it.
I created a simple GUI that would draw an 8x8 grid of "filled" and "empty" states, and output the array values to my perceptron.
![]()
Clicking on the boxes fills the squares in, and hitting enter sends the output out. So I try to draw a letter A with a little variance.
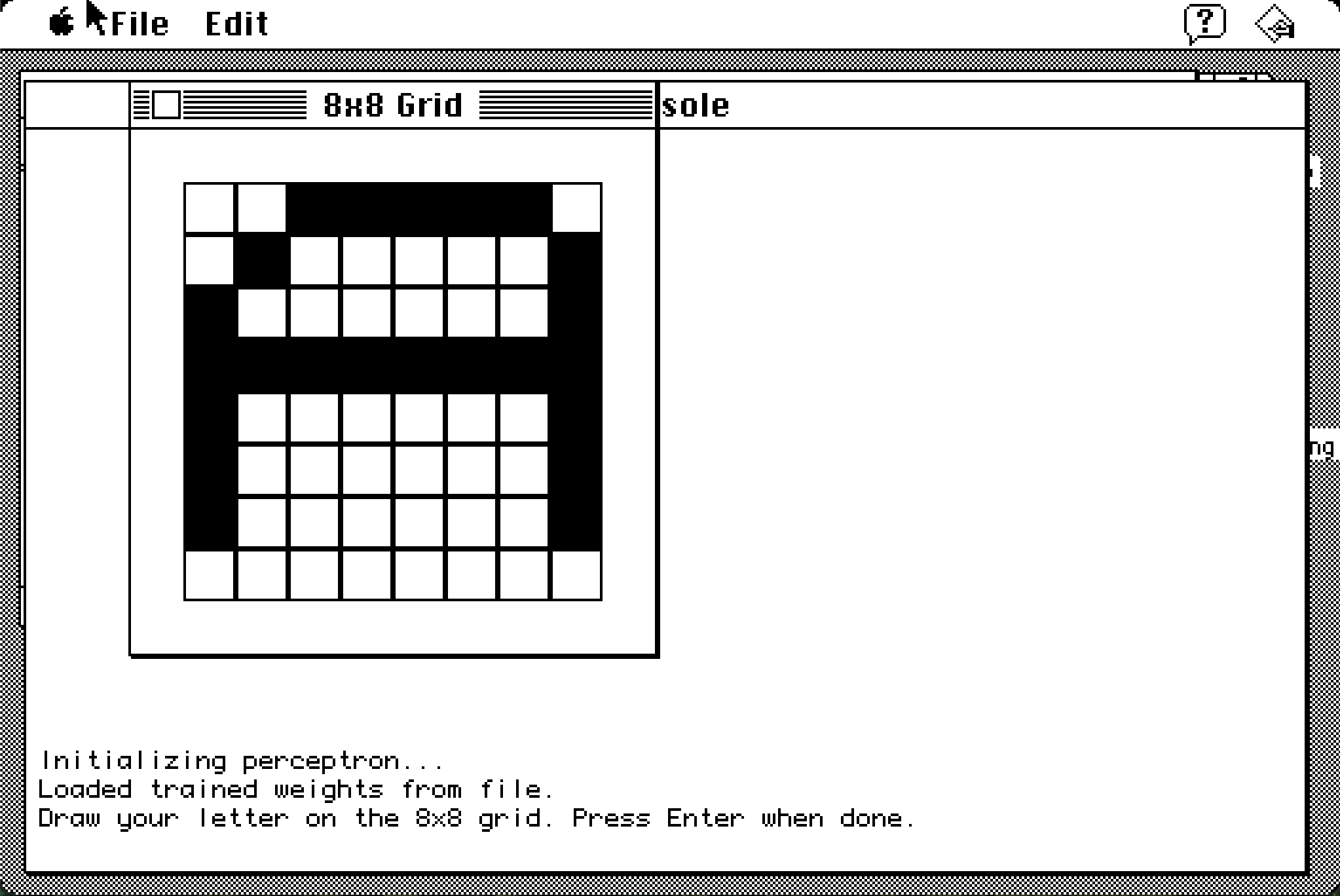
The output looks roughly like this:
double sample1[INPUT_SIZE] = {
0, 0, 1, 1, 1, 1, 1, 0,
0, 1, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0
};
The perceptron compares the binary data to its weights, and outputs the confidence that the image is an A.
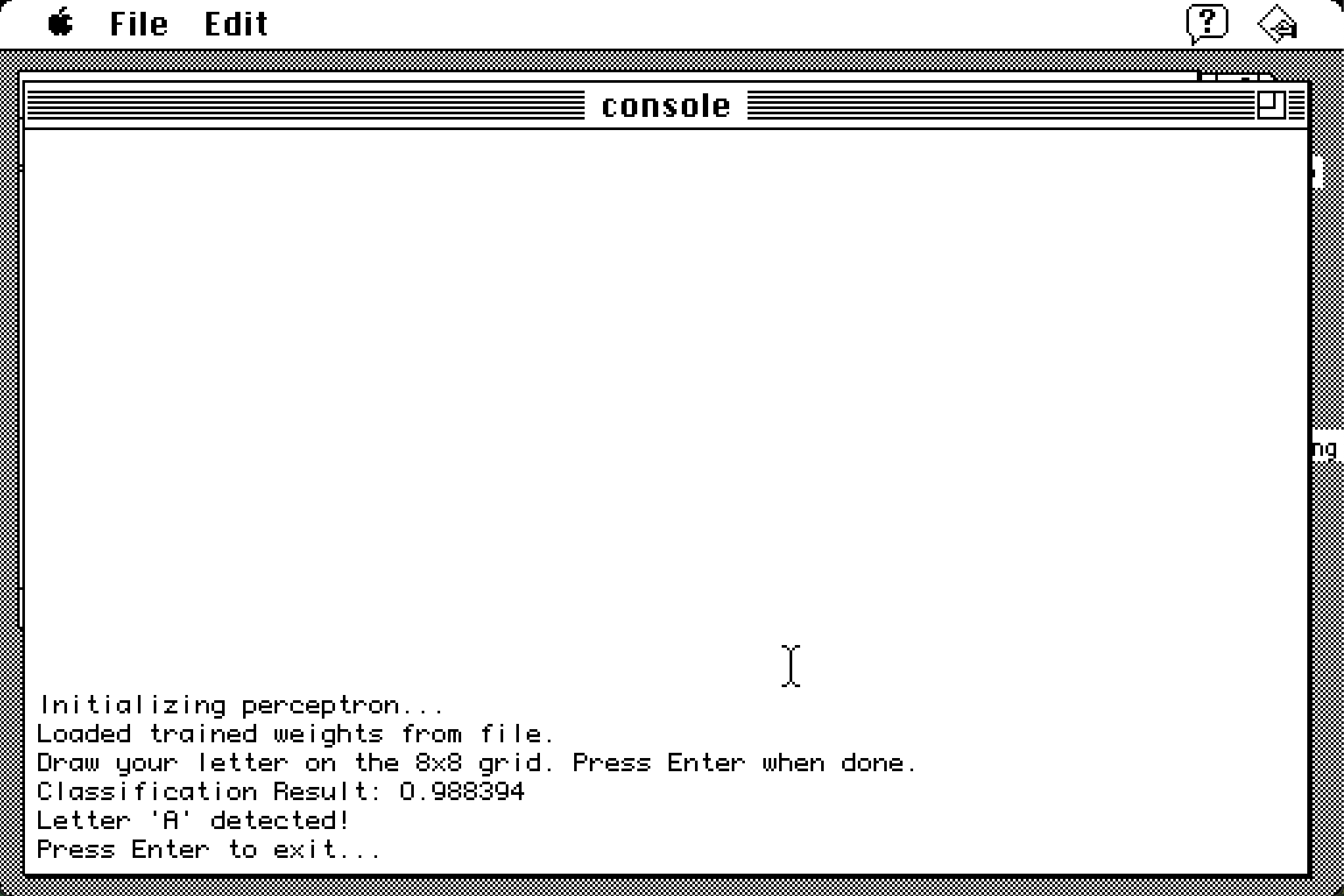
What's cool about this is that the training takes a bit of time, but outputs a binary weights file that can be used for inference on demand to save time.
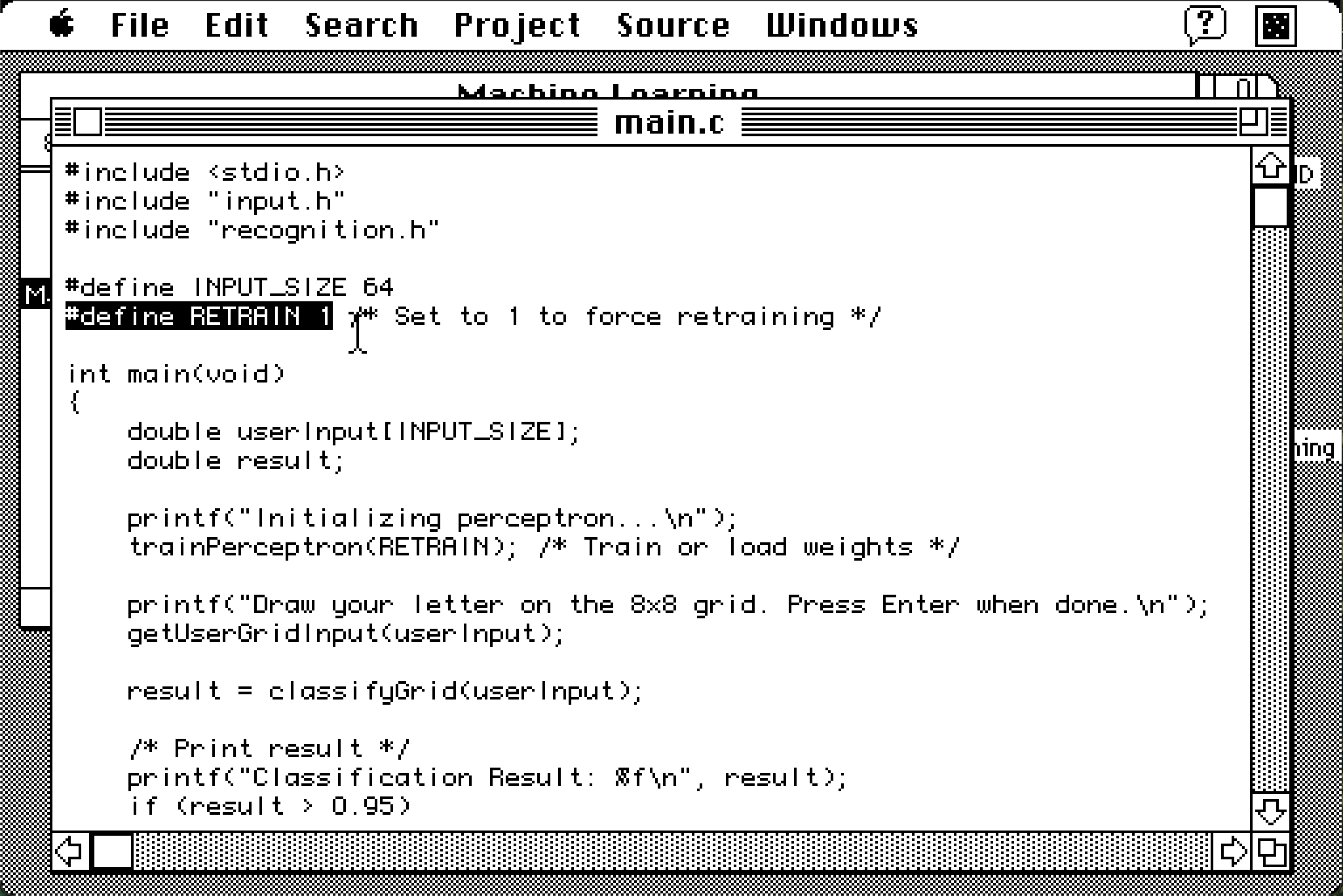
The training was done on only two samples, and has the most basic perceptron I could make with the resources I had:
void trainPerceptron(int retrain)
{
double learning_rate = 0.1;
int epochs = 100;
int epoch, i, j;
double sum, output, error;
if (!retrain && loadWeights())
{
printf("Loaded trained weights from file.\n");
return;
}
printf("Training perceptron...\n");
initTrainingData();
for (i = 0; i < INPUT_SIZE; i++)
{
weights[i] = ((double)rand() / (double)RAND_MAX) * 0.2 - 0.1;
}
bias = 0.1;
for (epoch = 0; epoch < epochs; epoch++)
{
for (i = 0; i < TRAINING_SAMPLES; i++)
{
sum = bias;
for (j = 0; j < INPUT_SIZE; j++)
{
sum += training_data[i][j] * weights[j];
}
output = sigmoid(sum);
error = labels[i] - output;
for (j = 0; j < INPUT_SIZE; j++)
{
weights[j] += learning_rate * error * training_data[i][j];
}
bias += learning_rate * error;
}
}
printf("Training complete. Saving weights...\n");
saveWeights();
}
Running inference was even simpler:
static double sigmoid(double x)
{
return 1.0 / (1.0 + exp(-x));
}
double classifyGrid(double input[INPUT_SIZE])
{
double sum = bias;
int i;
for (i = 0; i < INPUT_SIZE; i++)
{
sum += input[i] * weights[i];
}
return sigmoid(sum);
}
I could then save weights, and even compile everything into a single binary executable to save resources.
Conclusion
Learning how to run a simple machine learning program with such limited hardware was a really cool experience. Sometimes we get caught up in the abundance of resources, and libraries that do everything for us. But in this case, I didn't have any help. There aren't any programs like this out there that I could copy code from, and I only had a couple megabytes of RAM to work with, so the computer crashed a lot.
But it was worth it. I learned a lot about the core fundamentals of machine learning in its most basic form, and was able to use the same principles that Frank Rosenblatt used in the 1950s.
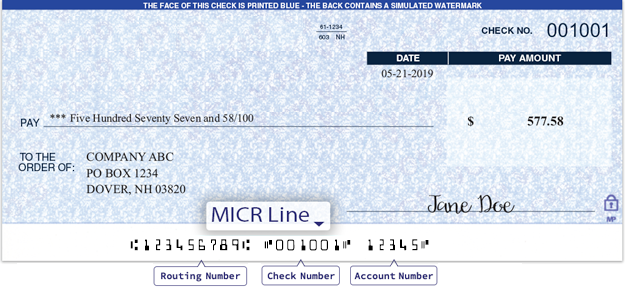
In fact, these are the governing principles of things as basic as barcode scanners, and even check readers. The MICR font on checks is a simple OCR problem that uses the same principles as the perceptron, however in that case they had to solve it for 1950s machines, and relied on counting black spaces on the text.
You can check out the source code for my project on Github.